Import Different Types of File in Python for Analysis - Part 2
In my previous tutorial I talked about how to import various type of file and work with it in Python when your file is in your local machine. This tutorial is the continuation of the previous tutorial but here I will be showing how import data from the www ( world wide web), api and so on and process these data for analyzing. You will learn about
- Importing flat file, such as text file from web
- Parsing HTML file and process HTML with Beautiful Soup package
- Import data from web api - twitter api
Importing necessary module
import requests
from urllib.request import urlretrieve, urlopen, Request
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Importing flat files from internet
To import flat data such as text or csv file we from web, firstly we need to specify the url, then we need to pass the url alone with the name of the file we want to save asto Python urlretrieve() function. It will save the file in our local machine. From there we can easily read the file the methods we learned earlier tutorial.
# assign url of file
url = 'https://s3.amazonaws.com/assets.datacamp.com/production/course_1606/datasets/winequality-red.csv'
# saving file in local machine
urlretrieve(url, 'imported_data/wine_red.csv')
# reading imported data
im_data = pd.read_csv('imported_data/wine_red.csv', sep= ';')
# printing few line
im_data.head(3)
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 1 | 7.8 | 0.88 | 0.00 | 2.6 | 0.098 | 25.0 | 67.0 | 0.9968 | 3.20 | 0.68 | 9.8 | 5 |
| 2 | 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15.0 | 54.0 | 0.9970 | 3.26 | 0.65 | 9.8 | 5 |
# importing data without saving locally
data = pd.read_csv(url, sep=';')
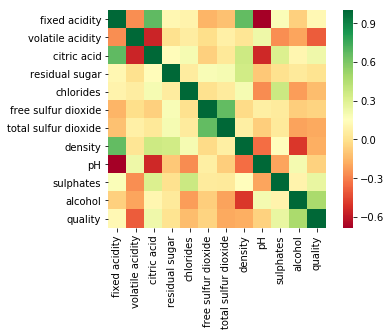
# plotting co-rel of data
sns.heatmap(data.corr(), square=True, cmap='RdYlGn')
<matplotlib.axes._subplots.AxesSubplot at 0x1e565dd8eb8>
importing non-flat file - Excelfile
We can import excelfile easily with pandas read_excel by passing the url and sheetname = “None”. We can analyze it as we wish.
# Assigning url of file
ex_url = 'http://s3.amazonaws.com/assets.datacamp.com/course/importing_data_into_r/latitude.xls'
# Reading data
ex_data = pd.read_excel(ex_url, sheet_name=None)
# printing sheetnames
print('Sheetnames\n', ex_data.keys(), '\n')
# printing first few line of 2nd sheet
print(ex_data['1900'].head(3))
Sheetnames
odict_keys(['1700', '1900'])
country 1900
0 Afghanistan 34.565000
1 Akrotiri and Dhekelia 34.616667
2 Albania 41.312000
performing http request using python
We can perform http reques to any web address using Python ‘requests’ package. We can just need to pass the url inside requests.get method and hold the object in variable. Later on we can extract information from that object using some fancy methods as follows.
import requests
# Specifying the url
url = 'https://sheikhhanif.github.io/project/'
# send request and catch response
res = requests.get(url)
# Extract the response
text = res.text
# printing data
print(text)
<!doctype html>
<html lang="en" class="no-js">
<head>
<meta property="og:title" content="Sheikh Hanif">
<meta property="og:url" content="https://sheikhhanif.github.io/project/">
</head>
<body class="layout--archive">
<p>Doing projects are always exciting. That is the place where we get chance to implement the knowledge we earned. Throughout my Computer Science degree, I have done many projects. All of them I didn’t preserved. Here is the list of projects I have done outside of my academic requirement to check out my own understading over the topics I learned.</p>
<div class="page__footer-copyright">© 2019 Sheikh Hanif</div>
</footer>
</div>
</body>
</html>
Parsing HTML with BeautifulSoup
In this part we will learn how to use beautifulsoup package to parse, prettify and extract information from HTML. This is quite handy while working with web data. It can process data efficiently. To learn more about ‘beautifulsoup’ refer to the official documentation.
# specifying url
url = 'https://sheikhhanif.github.io/project/'
# send request and catch response
res = requests.get(url)
# Extracting html
html_doc = res.text
# creating beautifulsoup object
soup = BeautifulSoup(html_doc)
# prettifying soup
pretty_soup = soup.prettify()
# printing the title of the url(soup)
print('url title: ', soup.title,'\n')
# printing text of it
print(soup.get_text())
url title: <title>Sheikh Hanif</title>
Doing projects are always exciting. That is the place where we get chance to implement the knowledge we earned. Throughout my Computer Science degree, I have done many projects. All of them I didn’t preserved. Here is the list of projects I have done outside of my academic requirement to check out my own understading over the topics I learned.
Building Scikit-Learn Linear Model: Elasticnet
Analyzing data and building a model using scikit learn. I used scikit learn elasticnet linear model and grid search cross validation to get the best result out of my data.
Go to Repository View Post
Online Encryption Decryption System.
A onlie ecryption decryption system using JavaScript where you can encrypt and decrypt your file.
Go to Repository View System
Follow:
Linkedin
GitHub
Feed
© 2019 Sheikh Hanif
# getting hyperlink
a_tags = soup.find_all('a')
for link in a_tags:
print(link.get('href'))
/
/data-science/
/project/
/about/
mailto:sheikhhanifhossain@gmail.com
https://github.com/sheikhhanif
https://linkedin.com/in/sheikhhanif
https://github.com/sheikhhanif/ElasticNet-Scikit-Learn.git
https://sheikhhanif.github.io/Scikit-Learn-Linear-Model-Elasticnet/
https://github.com/sheikhhanif/encryption.git
https://sheikhhanif.github.io/encryption/
https://linkedin.com/in/sheikhhanif
https://github.com/sheikhhanif
/feed.xml
Extracting data from API
Very often we need to use API to collect data. Such as facebook api, twitter api and so on. Each of these api has it’s own rule and regulation and documentaion for usage. Here I am showing extracting data from ‘omdb’ and twitter api. Please refer to the official documentation to use twitter api.
# Import package
import requests
# Assign URL to variable: url
url = 'http://www.omdbapi.com/?apikey=72bc447a&t=social+network'
# Package the request, send the request and catch the response: r
r = requests.get(url)
# Decode the JSON data into a dictionary: json_data
json_data = r.json()
# Print each key-value pair in json_data
for k in json_data.keys():
print(k + ': ', json_data[k])
Title: The Social Network
Year: 2010
Rated: PG-13
Released: 01 Oct 2010
Runtime: 120 min
Genre: Biography, Drama
Director: David Fincher
Writer: Aaron Sorkin (screenplay), Ben Mezrich (book)
Actors: Jesse Eisenberg, Rooney Mara, Bryan Barter, Dustin Fitzsimons
Plot: Harvard student Mark Zuckerberg creates the social networking site that would become known as Facebook, but is later sued by two brothers who claimed he stole their idea, and the co-founder who was later squeezed out of the business.
Language: English, French
Country: USA
Awards: Won 3 Oscars. Another 165 wins & 168 nominations.
Poster: https://m.media-amazon.com/images/M/MV5BOGUyZDUxZjEtMmIzMC00MzlmLTg4MGItZWJmMzBhZjE0Mjc1XkEyXkFqcGdeQXVyMTMxODk2OTU@._V1_SX300.jpg
Ratings: [{'Source': 'Internet Movie Database', 'Value': '7.7/10'}, {'Source': 'Rotten Tomatoes', 'Value': '95%'}, {'Source': 'Metacritic', 'Value': '95/100'}]
Metascore: 95
imdbRating: 7.7
imdbVotes: 556,761
imdbID: tt1285016
Type: movie
DVD: 11 Jan 2011
BoxOffice: $96,400,000
Production: Columbia Pictures
Website: http://www.thesocialnetwork-movie.com/
Response: True